 danuker | freedom & tech
danuker | freedom & tech I decided to review some programming languages, by comparing their popularity with their Rosetta Code implementation terseness.
I measured terseness as the average of implementations' estimated zipped code filesize.
Update 2021-01-17: After another enlightening Reddit discussion, I realized an even worse caveat of just looking at Rosetta Code snippets is the fact that some languages, like Clojure, need unit tests to reach the reliability offered by Haskell, which makes you define types upfront. The unit tests are not in Rosetta Code, but the type definitions are. Therefore, this analysis is even less relevant.
Update 2019-12-11: I want to add a few caveats that people notified me in this Reddit post:
- The analyzed source code includes comments, which might make up a lot of the code, like REXX.
- The tasks might use different algorithms in different programming languages. Hopefully this averages out, though.
- The compression did not do much. What I thought was it would be a better proxy for "difficulty" than raw source code, but it's the same. Here is the analysis with raw file sizes instead of zipped sizes.
- I'm not measuring what matters. Of course I'm not, what matters is different for everyone. I encourage you to use my Jupyter Notebook and create your own analysis. Also, send a comment over, I'm very curious what you thought of! Check out the "nomath" branch also.
I averaged various metrics of popularity (zeros when they were missing):
- The TIOBE index
- What languages people tend to migrate to on GitHub
- Number of Rosetta Code examples themselves (people must have had lots of dedication)
Because not all languages implement all Rosetta Code tasks, I had to estimate the length of the missing ones. I did this using the SVD++ matrix factorization algorithm in Surprise.
Also, many language-task pairs have multiple source code files. Sometimes there were multiple implementations, but other times it was just one implementation, but split across multiple files. In all cases, I ignored the pair (as if no examples existed).
Update 2019-11-27: I also filtered the tasks to non-math ones that I handpicked.
I could then compute statistics about the longest programs, and the shortest languages.
Still, I didn't want code golf craziness from here (nor code golf craziness from there). So, I also looked at the popularity of languages.
Non-Math Map
Update 2019-11-27: Here is a map of the languages, in popularity vs. code size on non-math tasks handpicked by me, with the Pareto-nondominated space in green:
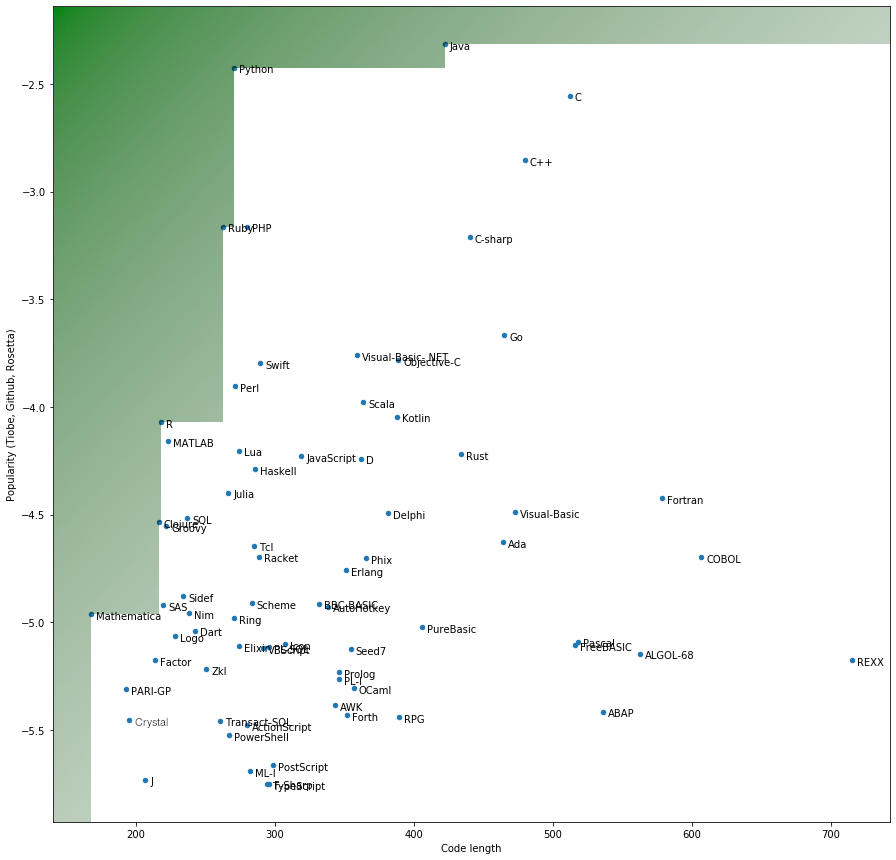
Overall Map
Here is the old map, with all the Rosetta Code tasks, including lots of numerical/math ones:

Comments
My analysis found quite a few interesting languages. The most condensed were:
| Language | Average estimated code (zipped bytes) |
|---|---|
| Burlesque - crazy code golf language | 110.36 |
| Excel - sadly, not usable outside spreadsheets | 115.15 |
| IDL - "Interactive Data Language"; commercial but has a free clone | 141.71 |
| GUISS - a Windows GUI automation language | 144.67 |
| TI-83-BASIC - a Texas Instruments calculator language | 144.97 |
| PARI/GP - a computer algebra system | 145.51 |
Not all of these are useful programming languages (they are very domain-specific).
But PARI/GP, while not very popular, had 440 samples in Rosetta Code when my dataset was created. A pretty comprehensive set if you ask me! It has programming capabilities. The fact that it was written by mathematicians for mathematicians intrigues me; I will check it out (I could easily install the pari-gp Debian package then run gp). If it is flexible enough, it should be much easier to write code in! I will set the unpopularity threshold a bit below this language.
Edit 2019-11-27: After looking at non-math tasks, I chose to study R and Clojure first, instead of this algebra system; it is no longer on the Pareto frontier when including Mathematica (but it is still close).
It seems Mathematica's language, a proprietary one, is also quite condensed. I don't want to learn it because it's proprietary and quite locked-in - even their tutorials show pictures instead of copyable code.
The third one that caught my eye was MATLAB. I did not expect it to be so terse, I did not think it so when I was using it during college. The reason might have been not knowing its vast library of in-built functions. A libre version is called Octave, which is also slightly terser, but was not on any popularity list. Still, many MATLAB scripts run as they are in Octave.
Clojure (new on the Pareto frontier as of 2019-11-27) - After considering just non-math tasks, Clojure reaches the frontier, albeit not much better than R. Clojure is a lisp-like language on the JVM.
R is a free-software statistical computing language. I am liking it a lot, and it is very popular among data scientists. If I can not learn or use PARI/GP, I will try my brain at R.
Ruby and PHP are very popular languages, built with the Web in mind. I have used Ruby professionally and I love it, it really is perceptibly denser than Python. Here is an example in an irb session:
> 3.even?
=> false
Here, I am "asking" the number 3 whether it is an even number. Notice the question mark, a useful convention to remind yourself that the return value is a boolean. Contrast to the Python way, which has no support for this:
>>> 3 % 2 == 0
False
Tiny cases like this add up, and I am not surprised Ruby is objectively terser.
The reason I didn't stick with Ruby is because its numerical computing ecosystem is not as developed as Python's. But it is growing.
As for PHP, I have not had much experience with it, and I'm surprised that it's shorter than Python (albeit only slightly).
Python is my current workhorse. This analysis is done using Python (with Pandas and the Mathematica-inspired Jupyter-Notebook, which can actually be used with many languages, including PARI/GP). It has a large and fast-growing user base, great support for a wide range of applications, and can be sped up via C extensions (as many computing libraries do).
Java is a more verbose language. I remember code "patterns" that led to something similar to StudentFactoryManagerObserverFacadeController, and don't want to go back there. Still, it is arguably the most popular language (though Python ~~will most likely outgrow it~~ might have outgrown it in some areas).
Hardest tasks
Update 2019-12-11
The factorization was also useful for detecting the tasks that took the most code, independent of programming language.
They might serve as inspiration for "extreme" difficulty coding interview tasks.
| Task | Average expected code length |
|---|---|
| Minesweeper-game | 1128.487693 |
| MD5-Implementation | 1056.812754 |
| Stable-marriage-problem | 1001.869361 |
| The-ISAAC-Cipher | 992.001283 |
| Tic-tac-toe | 963.968912 |
| Honeycombs | 952.617747 |
| Zebra-puzzle | 950.222265 |
| K-means++-clustering | 831.377990 |
| Total-circles-area | 828.344111 |
| Sudoku | 820.059907 |
Conclusion
Do not take this analysis too seriously. It has inaccuracies, and was done as a hobby/curiosity, not a formal scientific experiment.
Still, I hope you learned something from this analysis. Sure, code length is not an end-all be-all metric, but short code might be easier to work with (at the expense of being harder to learn initially). I would appreciate your answer about any of the following:
- What do you think of your programming language? Is it close to the Pareto frontier?
- Is the Rosetta dataset too artificial of a comparison?
- Does my analysis reflect reality?
- Did it help you choose a new language?
The Jupyter notebook and popularity data for this analysis are available here. Check out the "nomath" branch also.
Comments