 danuker | freedom & tech
danuker | freedom & tech I shared my previous post on Reddit, and I got some very useful feedback which pointed out the irrelevance of what I was measuring (and also a scientific paper pointing out many statistical errors in a "real" GitHub study).
So, I figured I'd measure something more relevant: bugs.
Caveats
Sadly, there is no cheap way of measuring bugs due to language. What I did was similar to the paper criticized in the paper above, but with much fewer projects (roughly 20 per language), and a much simpler pipeline.
- This is not a scientific study. It is an informal hobby analysis, for discovering fun facts and/or languages. Use at your own risk!
- Correlation is not causation. Just because there are more bugfix commits in a language, doesn't mean the language is at fault.
- The difference might be caused by something else, such as developer experience, or the use cases of the language, or the way the language is used.
- I did not correct for developer experience, number of developers, project size, or many other factors. When you create a model taking such variables into account, and holding them constant, you might get less overlap between languages.
- The detection of bug/fix commits is very primitive: whatever is being returned by the GitHub query "fix OR fixed OR bug". This could be improved by using neural networks and somesuch (I would recommend character-level, in the case of commit messages). Also, the linked paper uses Bonferroni adjustment to mitigate the error rate, but I didn't, because I don't know what the error rate is in my case.
- There may still be unfixed bugs in the analyzed repositories (at least those reported as issues, but not yet fixed).
What did I do
- Search for the programming language's name, and then click on the programming language itself as a filter
- Get top GitHub projects sorted by "most forked"
- Eliminate projects which are about learning or collections of other software
- Try to eliminate projects which, as a commit message policy, use "Fix" or "Bug" even for new features added
- Eliminate projects with less than 200 commits
- Eliminate projects with less than 75% of it being the main programming language
- Only keep one project per language from each GitHub account
- For each project, divide number of bug commits by total commits
I have breached a few rules with Mathematica and Jupyter Notebook, because it was very difficult to find code with these constraints. Example: this is a learning/tutorial project with both R and Python.
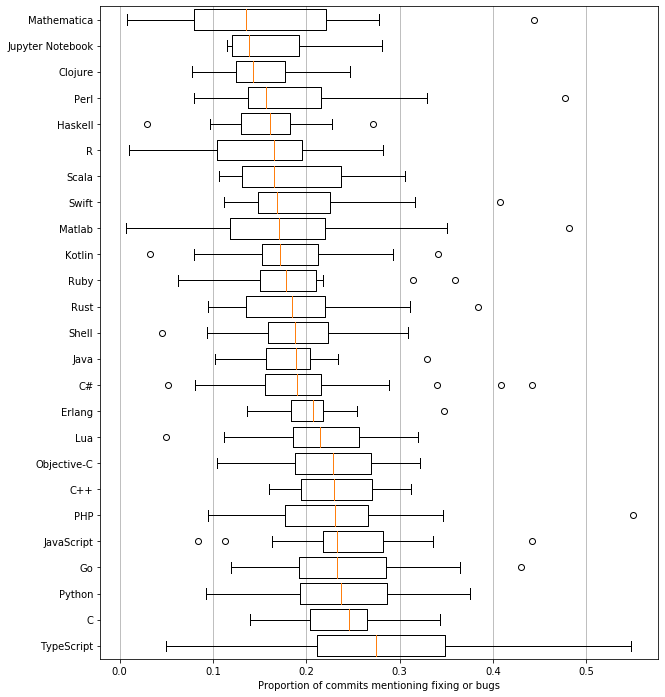
Boxplot
In spite of the aforementioned limitations, I produced a pretty Matplotlib boxplot.
The boxplot boxes show the interquartile range (IQR - 25th percentile to 75th percentile). The median (50th percentile, or value that splits the data in two halves) is in red. The whiskers are not modified from the default whis behavior, covering data 1.5 IQRs above and below (right and left actually, in this image) the box ends themselves. Anything more than 1.5 IQRs away are outliers (marked with circles).
Conclusion
While this analysis was fun, it was not very informative. As you can see, there is significant overlap, even if we used the IQR which covers 50% of data, much less than the 95% confidence interval required for a typical statistical test. Even JavaScript's lower whisker is lower than any language's 75% percentile.
This means there is a lot of variation between projects within the same language, so much so that we can not tell which languages are better.
I added some Jupyter Notebook repositories, because I suspected Mathematica and Clojure use the REPL a lot, which I suspect leads to more testing of the code and fewer bugs committed. It seems using a REPL might have a positive influence, seeing that the median gets between Clojure and Mathematica, though again, that might not mean much - there are many "suspect" links there, and many Jupyter projects are for learning and/or presentation purposes, which might influence bugfix rates (I couldn't get around that, because there're so few with sufficient commit counts).
Still, I think I will try out Clojure. The low fix rate (~14% of commits compared to Python's ~23%) might mean I'll learn something.
As usual, you can find the Jupyter Notebook on my GitHub repository.
Comments