 danuker | freedom & tech
danuker | freedom & tech Take Uncle Bob's Clean Architecture and map its correspondences with Gary Bernhardt's thin imperative shell around a functional core, and you get an understanding of how to cheaply maintain and scale software!
This is what Mr. Brandon Rhodes did. It's not every day that I find such clear insight.
I am honored to have found his presentation and slides explaining Uncle Bob's Clean Architecture and Gary Bernhardt's PyCon talks of 2011, 2012, and 2013.
Mr. Rhodes offers such a distilled view, that he can show you these crucial concepts in 3 slides of code. I will go ahead and summarize what he said and add a tiny bit of my insight.
Copyright of all Python code on this page belongs to Mr. Brandon Rhodes, and copyright of the diagram belongs to Robert C. Martin (Uncle Bob). Edit 2020-11-17: I use these with permission from the authors - they are not under the same CC-BY license as the rest of my blog.
Mr. Rhodes warmly recommends the Harry Percival and Bob Gregory book Architecture Patterns with Python, also known as "Cosmic Python". It also talks about the Clean Architecture. You can do any or all of the following:
- Buy it as a DRM-free ebook on ebooks.com
- Order it from Amazon.com or Amazon.co.uk
- Read it for free on the Cosmic Python website (it is under a CC-By-NC-ND license).
- Hack the source code or fix typos on GitHub
I can't wait to read it myself.
Glossary
First of all, we need to be on the same page, in order to be able to understand each other. Here are the words I'll use:
- Function: I use "function" or "pure function" to refer to a Python "function" that only uses its parameters for input, returns a result as output, and does not cause any other side-effects (such as I/O).
- A pure function returns the same output given the same inputs.
- A pure function may be called any number of times without changing the system state - it should have no influence on DB, UI, other functions or classes.
- This is very similar to a mathematical function: takes you from x to y and nothing else happens.
- Sadly we can't have only pure functions; software has a purpose of causing side-effects.
- Procedure, Routine, or Subroutine: A piece of code that executes, that may or may not have side effects. This is a "function" in Python, but might not be a "pure function".
- Tests: automated unit tests. By "unit" I mean not necessarily just a class, but a behavior. If you want, see more details in the coupling chapter of my previous post.
Listing #1: Complex code
import requests # Listing 1
from urllib import urlencode
def find_definition(word):
q = 'define ' + word
url = 'http://api.duckduckgo.com/?'
url += urlencode({'q': q, 'format': 'json'})
response = requests.get(url) # I/O
data = response.json() # I/O
definition = data[u'Definition']
if definition == u'':
raise ValueError('that is not a word')
return definition
Here, we have a piece of code that prepares a URL, then gets some data over the network (I/O), then validates the result (a word definition) and returns it.
This is a bit much: a procedure should ideally do one thing only. While this small-ish procedure is quite readable still, it is a metaphor for a more developed system - where it could be arbitrarily long.
The current knee-jerk reaction is to hide the I/O operations somewhere far away. Here is the same code after extracting the I/O lines:
Listing #2: Hiding I/O at the bottom
def find_definition(word): # Listing 2
q = 'define ' + word
url = 'http://api.duckduckgo.com/?'
url += urlencode({'q': q, 'format': 'json'})
data = call_json_api(url)
definition = data[u'Definition']
if definition == u'':
raise ValueError('that is not a word')
return definition
def call_json_api(url):
response = requests.get(url) # I/O
data = response.json() # I/O
return data
In Listing #2, the I/O is extracted from the top-level procedure.
The problem is, the code is still coupled - call_json_api is called whenever you want to test anything - even the building of the URL or the parsing of the result.
Coupling kills software.
A good rule of thumb to spot coupling is this: Can you test a piece of code without having to mock or dependency inject like Frankenstein?
Here, we can't test find_definition without somehow replacing call_json_api from inside it, in order to avoid making HTTP requests.
Let's find out what a better solution looks like.
Listing #3: I/O at the top
def find_definition(word): # Listing 3
url = build_url(word)
data = requests.get(url).json() # I/O
return pluck_definition(data)
def build_url(word):
q = 'define ' + word
url = 'http://api.duckduckgo.com/?'
url += urlencode({'q': q, 'format': 'json'})
return url
def pluck_definition(data):
definition = data[u'Definition']
if definition == u'':
raise ValueError('that is not a word')
return definition
Here, the procedure at the top (aka. the imperative shell of the program) is handling the I/O, and everything else is moved to pure functions (build_url, pluck_definition). The pure functions are easily testable by just calling them on made-up data structures; no Frankenstein needed.
This separation into an imperative shell and functional core is an encouraged idea by Functional Programming.
Ideally, though, in a real system, you wouldn't test elements as small as these routines, but integrate more of the system. See the coupling chapter of my previous post to understand the trade-offs.
Functional Core / Imperative Shell vs. Clean Architecture
Look at Uncle Bob's Clean Architecture chart (Copyright Robert C. Martin aka. Uncle Bob) :
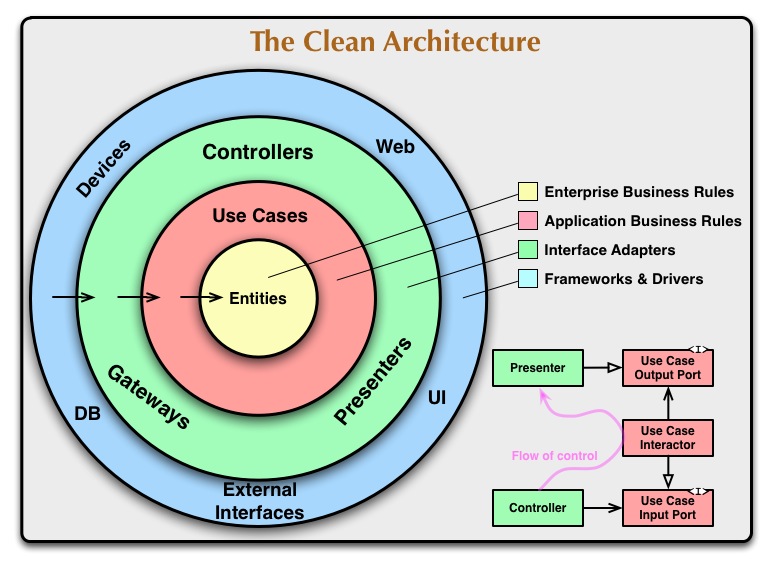
Uncle Bob's Use Cases and Entities (red and yellow circles of the chart) map to the pure functions we saw earlier - build_url and pluck_definition from Listing 3, and the plain objects they receive as parameters and send as outputs. (updated 2020-10-28)
Uncle Bob's Interface Adapters (green circle) map to the top-level imperative shell from earlier - find_definition from Listing 3, handling only I/O to the outside (Web, DB, UI, other frameworks).
Update 2020-10-28: A "Model" object in today's MVC frameworks is a poisoned apple: it is not a "pure" object or "humble" object, but one that can produce side effects like saving or loading from the database. Their "save" and "read" methods litter your code with untestable side-effects all over. Avoid them, or confine them to the periphery of your system and reduce their influence accordingly (they are actually a hidden Interface Adapter) due to interacting with the DB.
Notice the arrows on the left side of the circles, pointing inwards to more and more abstract parts. These are procedure or function calls. Our code is called by the outside. This has some exceptions. Whatever you do, the database won't call your app. But the web can, a user can through a UI, the OS can through STDIN, and a timer can, at regular intervals (such as in a game). (updated 2020-10-28)
The top-level procedure:
- gets the input,
- adapts it to simple objects acceptable to the system,
- pushes it through the functional core,
- gets the returned value from the functional core,
- adapts it for the output device,
- and pushes it out to the output device.
This lets us easily test the functional core. Ideally, most of a production system should be pure-functional.
Benefits
If you reduce the imperative shell and move code into the functional core, each test can verify almost the entire (now-functional) stack, but stopping short of actually performing external actions.
You can then test the imperative shell using fewer integration tests: you only need to check that it is correctly connected to the functional core.
Having two users for the system - the real user and the unit tests - and listening to both, lets you guide your architecture so as to minimize coupling and build a more flexible system.
Having a flexible system lets you implement new features and change existing ones quickly and cheaply, in order to stay competitive as a business.
Comments are much appreciated. I am yet to apply these insights, and I may be missing something!
Edit 2020-10-28: I have tried out this methodology in some small TDD Katas, and together with TDD, it works great. But I am not employed right now, so I can't say I've really tried it.
Comments